1. 배경
chatgpt 4o 가 일반화되는 상황에서, LLM으로 사람이 하는 모든 행위(보고, 듣고, 말하고, 생각하는)를 구현할수 있게 된다. 과거라면, 모델을 직접 만들어야지 내가 직접했다고 할수 있지 않나 라는 생각을 하게 되는데, 지금의 세상은 돈이라는 자원과 인력, 시간이 많으면 많을 수록 좋은 결과를 만들어낼 수 있는 상황이 되고, 개인이 이를 따라가기에는 불가능 수준에 가까워지고 있다고 여겨진다.
잘난 사람들과 잘난 기업에서 잘 만들어진 인공지능 모델을 이용하여, 생활에 활용하는 응용을 만드는 영역에서 개인이, 그리고 일반 기업이 역할을 맡아서 좋은 서비스를 계속 만들어내지 않을까 하는 생각이다. 영어 학습용 앱 중에 스픽이라는 것이 있다. 이것과 LLM서비스와 연결을 하여, 학습튜터링과 대화 대상이 되도록 하고, 영어 문장을 깔끔하게 교정을 해주는 것으 그 사례로 생각된다. 스픽앱에서 chatgpt API와 연결했다는 얘기를 들었던 기억이 있다.
지금 상황을 보면, LLM으로 모든 것을 처리할 수 있는 것으로 보이지만, 그 서비스를 사용하려면 온라인 서비스를 비용 지불하여 사용하거나 해야 한다. (당연히, 무료로 제공되는 좋은 모델들도 많다.)
신분증의 이름, 발급일자 등의 정보를 얻어서 텍스트로 인식을 할 수 있도록 하기 위해서는 tesseract ocr 을 사용하던 경우가 많이 보였었다. 그리고, 이미지 인식을 하는 용도로는 yolo 모델을 사용하는 경우 등 특화된 모델을 이용해서 개별 응용프로그램을 만드는 데 활용하는 것이 일반적이라 생각된다.
2018년이었을까. tesseract의 머신러닝을 이용해서 이미지에서 텍스트를 뽑아내는 것을 시험해보고, 이것을 접근제어솔루션에 적용해보았다. 윈도우의 이미지를 파일로 기록해서 사고 발생했을 때의 역추적을 위한 용도로 사용하고 있었는데, 이것은 사고가 난 뒤의 원인을 찾는 용도로만 사용될 수 밖에 없기에 윈도우의 이미지를 사람이 아닌, 머신이 자동으로 분석하여 이상행위를 찾는 것을 만들어보았다. 하루에 100만장 이상 생성되는 이미지를 검색하고 tesseract ocr 을 이용해서 텍스트로 변환시켜서 주민번호 또는 불법SW를 사용한 여부를 찾도록 해보았다.
그 결과는 생각보다 좋은 결과를 만들어냈다. 주민번호를 DB에 저장하고 있는 서비스도 있었고, 운영자가 이를 조회한 화면에서 주민번호 조회된 Case를 찾아낼 수 있었다. 그리고, 운영자들의 운영시스템을 개인PC처럼 사용하는 오용하는 사례를 찾아서 개선할 수 있었다.
이번에 내용 설명을 하려는 것은, 몇 년전 부터 짬짬이 해왔던 것을 정리하는 차원에서, 그리고 개인적으로 재미있는 영역이어서 나중에 다시 진행하더라도 기억을 하기 위해서라도 정리해보았다.
간단한 방법으로도 사물을 인식하여 여러가지 응용프로그램을 만들수 있다는 과정을 기계적으로 따라갈 수 있도록 했다.
모든 것은 최초 배울 때, 역사, 이론공부 부터 시작해서 해야되는 일반적이고 정석적인 과정이 있지만, 시간적인 제약으로 아주 급조해서 결과를 만들어내려면, 이런 내용은 생략하였다. 학부 졸업한 지 오래 되어서, 회귀분석, 분산분석, 실험계획법 시간에 배웠던 내용이 가물가물해서 설명도 못하겠고... 누군가가 만들어 둔 아주 좋은 모델을 가져와서 사용하는 사용자 수준에서, 그리고 그것을 이용하여 응용프로그램을 만드는 일반 개발자로서, 기계적으로 따라가게 요약했다.
2. 준비 사항
- 하드웨어
- GPU서버가 있으면 속도가 빨라서 좋겠지만, GPU서버가 없다고 해서 배울수 없는 것은 아니다. 배울수 있다. LG그램 노트북으로 진행한다. 여기에서 응용 프로그램을 만들 수준은 충분하다.
- 소프트웨어
- 파이썬3.8 이상
- 이미지 인식 위한 모델은 YOLO v5를 사용하였다.
- 그외 필요한 패키지들이 좀 더 있는데, 아래에 표시한다
- CPU에서 이미지 1장 인식하는데 1초 이내에 처리되는 것 같긴하다. 물론, TensorRT를 사용하는 경우, 5~6배 이상 속도를 높일수도 있다.
3. 소프트웨어 설치
- 파이썬 설치
- 설치 주소: https://www.python.org/downloads/
- 내용: 최신버전을 설치하면 된다. 기존에 했던 것은 3.8.6을 설치했었기에 그 기준으로 기록한다.

-
- 설치가 완료되면, PC의 Path 환경변수를 추가해서 python명령어를 어디서든 호출할 수 있도록 한다.

-
- 맨 아래에 있는 환경변수를 선택한다.

-
- 시스템 변수와 사용자변수의 Path를 각각 편집한다.

-
- 환경변수 편집에는 설치한 파이썬 인터프리터와 Scripts폴더를 찾아서 추가한다. 아래 예는, 파이썬을 ProgramFiles에 설치하지 않고 사용자 계정에 설치한 경우여서, 개인폴더를 입력하였다. 굳이 왜 사용자 계정에 한정해서 설치했었는지 기억이 안난다. T.T


-
- 이제 설정이 되었는지 확인하기 위해, "명령 프롬프트"를 열어서 "python.exe"와 "pip.exe"를 입력하여 실행해보자. 아래와 같이 나오면, 정상적으로 설치한 것이다. python인터프리터의 종료는 quit()를 사용한다.

-
- 위의 일련의 작업들은 제일 단순하게 command창에서 사용하기 위해 진행한 것인데, pycharm 이나 vscode 등의 IDE를 사용하는 것이 더 편하다.

- YOLO v5 설치 (You Only Look Once: Unified, Real-Time Object Detection)
- 주소: https://github.com/ultralytics/yolov5
- 설치방법은 git 를 이용해서 다운로드 받아서 설치해도 된다. git이 설치 안되어있으면 위의 주소에 접속해서 초록색이 "Code"를 선택하고 ZIP파일을 다운로드 받아서 사용해도 된다.

-
- 다운로드 받은 파일은 "D:\work\yolov5"에 압축을 풀어놨다. zip파일로 받은 것은 yolov5-master로 되어있는데, 길어서 "-master"는 삭제하였다.

-
- yolov5 을 위한 필수 패키지를 설치한다.

-
- 아래와 같이 진행된다. 가상환경을 만들어서 아래의 패키지를 설치 진행하는 것이 좋은 방법이기는 하다. 가상환경을 만들어서 진행하면, 진행중에 잘못했을 때, 지우고 다시 설치하는 것도 쉽다.

-
- 최종 설치 완료되면, 아래와 같이 나온다. 맨 마지막에 "경고" 메시지가 나오는 것은 무시해도 되고, 거기에 나온 것과 같이 명령어를 입력해서 프로그램을 업데이트하면 된다.

-
- 위에서 나온 경고문구를 없애기 위해서, 20.2.1 버전의 pip를 uninstall하고 24.0으로 업그레이드 했다.

4. 프로그램 시험
- YOLOv5 설치 시험
- PC의 카메라를 이용해서, 이미지 인식이 되는지 시험을 하자.
- YOLOv5가 설치된 "D:\work\yolov5"에서 아래 명령을 입력한다. source 뒤의 0은 기본 웹캡을 지정한 것이고, 0 대신에 동영상파일을 입력해도 된다.
- 명령: python detect.py --source 0

-
- 최초 설치할 때, 아래와 같이 진행된다. 실행되는 파라미터는 나중에 알아보면 되고, yolov5s.pt 파일을 자동으로 다운로드 받게 된다.

- YOLOv5s를 다운로드 받는 방법은, 아래의 github에서 다운로드 받을 수 있다. 다운로드를 한 파일을 "D:\work\yolov5"폴더에 넣어두면 된다. 아래의 도표를 보면, 밑으로 갈 수록 인식되는 수준은 높아지지만, 당연히 속도는 늦다. 제일 빠른 것은 YOLOv5n 모델이다.

-
- 동일 폴더에 학습된 모델이 있다면, 반복 다운로드 하지는 않는다. 여기서 제공되는 모델은 80개의 사물에 대한 학습을 해둔 것이라서, 일반적인 시험을 쉽게 진행할 수 있다. 그리고, 사물 인식을 하기 위한 모델을 아래와 같이 선택해줄 수 있다. 인식 오차는 많이 있지만, 속도가 아주 빠른 놈(yolov5n.pt)으로 실행한 사례도 같이 넣어서 비교를 해보았다. ( --weights 파라미터를 이용하여 사용할 모델을 지정해준다 )
-
- 사물 리스트(80종)
|
0: person
1: bicycle
2: car
3: motorcycle
4: airplane
5: bus
6: train
7: truck
8: boat
9: traffic light
10: fire hydrant
11: stop sign
12: parking meter
13: bench
14: bird
15: cat
16: dog
17: horse
18: sheep
19: cow
20: elephant
21: bear
22: zebra
23: giraffe
24: backpack
25: umbrella
26: handbag
27: tie
28: suitcase
29: frisbee
30: skis
31: snowboard
32: sports ball
33: kite
34: baseball bat
35: baseball glove
36: skateboard
37: surfboard
38: tennis racket
39: bottle
40: wine glass
41: cup
42: fork
43: knife
44: spoon
45: bowl
46: banana
47: apple
48: sandwich
49: orange
50: broccoli
51: carrot
52: hot dog
53: pizza
54: donut
55: cake
56: chair
57: couch
58: potted plant
59: bed
60: dining table
61: toilet
62: tv
63: laptop
64: mouse
65: remote
66: keyboard
67: cell phone
68: microwave
69: oven
70: toaster
71: sink
72: refrigerator
73: book
74: clock
75: vase
76: scissors
77: teddy bear
78: hair drier
79: toothbrush
|
-
-
- python detect.py --source=0 --weights yolov5s.pt
인식된 속도가 300msec 정도 나오고, 가끔 사람이 아닌, Dog로 인식되는 경우도 있다.
- python detect.py --source=0 --weights yolov5s.pt
-

-
-
- python detect.py --source=0 --weights yolov5n.pt
인식 속도가 150msec 전후로 yolov5s보다 좀 더 빠르게 인식하지만, 사람을 인식 시켰는데도 dog로 오인식하는 경우가 더 자주 발생된다.
- python detect.py --source=0 --weights yolov5n.pt
-

-
-
- python detect.py --source 0 --weights yolov5x.pt
인식은 오류없이 사람으로 인식이 잘되지만, CPU로만 돌아가는 그램노트북으로 인식하는데, 2.2초 정도 걸린다.
- python detect.py --source 0 --weights yolov5x.pt
-

- 시험2
- 노트북의 카메라가 아닌, USB카메라를 연결하여 시험한 내용이다. 추가된 웹캠의 번호는 그 다음 순번인 "1"이 된다.

거실의 TV와 TV내의 출연한 사람에 대한 인식결과인데, 왼쪽의 어두운 부분에 있는 Laptop(36% 확율)은 잘못 인식된 것이다. 추정치로 나온 것이니, 이이 값을 근거로 50%가 넘는 것을 또는 60% 넘는 것만 정상적인 것으로 인정하는 방법으로 응용프로그램에서 활용할 수 있다.

- 사진 파일을 갖고, 사물 인식을 해보자.
- 에디터에서 아래의 파이썬 프로그램을 작성하고 저장한다. Local에 이미지를 다운로드 받아서, 로컬에 있는 이미지 경로를 입력해도 된다.
- 파일명은 detect2.py 라고 저장하였다. 이 프로그램은 yolov5 모델을 이용하여, 인터넷의 "zidane.jpg"사진 파일에 있는 사물을 인식하고 화면에 해당 결과를 이미지와 텍스트로 표시하게 한 프로그램이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
import torch
# Model
model = torch.hub.load("ultralytics/yolov5", "yolov5s") # or yolov5n - yolov5x6, custom
# Images
img = "https://ultralytics.com/images/zidane.jpg" # or file, Path, PIL, OpenCV, numpy, list
# Inference
results = model(img)
# Results
results.show()
results.print()
|
{kind=link}
{kind=link}
-
- 에디터로 작성한 샘플 자료

-
- 원본 사진

- 결과는 다음과 같다.
- 실행한 결과: 사람2명과 타이 2개 인식

-
-
- 위의 텍스트로 결과 출력한 것과 동일하게 사람2명과 넥타이 2개 인식한 사진
-

5. Training
- Training은 무엇일까?
- 지금까지 시험해본 것은 여러 사물에 대해 기본적으로 제공되는 학습된 것(128개 사물)을 사용해보았다.
- 내가 어떤 프로그래밍을 할지에 따라서 학습을 시킬 대상이 달라질 것이다. 예를들어, 자동차 번호판을 인식해서 차량 번호를 읽어들이려 한다면, 이미지들 중에서 차량 번호판이 어떤 모양으로 된 것인지를 지정을 해주고, 이 yolov5 모델을 이용하여 학습을 시켜서 새로운 사물에 대해 인식시킬 수 있도록 한다.
- 운전을 할 때, 교차로에서 대기할 때 신호등이 초록색으로 바뀌었을 때, 또는 좌회전 신호로 바뀌었을 때, 이를 인식해서 소리로 안내를 해주는 것을 만들어 보려 한다면, 어떻게 해야할까?!!!(나는 이것을 와이프2.0 이라 칭했다)
당연히, 차가 교차로에 서 있을 때에 보게되는 다양한 신호등 사진을 갖고, 초록색 신호등과 빨간색 신호등, 좌회전 신호등을 구분하여 컴퓨터에서 알려줘야지, 컴퓨터가 학습할 수 있는 방식이다. 이것을 지도학습이라고 한다.
- 학습을 하기 위해서는 많은 이미지를 구해야 한다. 블랙박스의 동영상에서 교차로 사진만 뽑아내는 것도 좋지만, 카메라 화질 차이로 인해 학습된 결과와 실제 추론할 대상 이미지가 달라서 다른 사물로 인식되는 경우가 있을 것 같아서, 실제 사용할 카메라를 차에 설치하고 동영상을 촬영한 후, 교차로에서 다양한 형태의 신호등 사진을 저장하였다. 실제 사용한 것은 500여장 되지만, 초기 실험을 위해서는 2~30여장으로 진행을 했었는데, 괜찮은 결과가 나왔었다.



- 라벨링이 필요하다.
- 당연히, 컴퓨터가 위의 사진만 갖고 스스로 알아서 초록색 신호등과 좌회전 신호를 인식하지는 못한다. 이를 인식시키기 위해, 수작업으로 인형에 눈알 붙이듯이 이미지마다 인식을 시켜주는 라벨링을 해야 한다.
- 라벨링을 하기 위해, 조금 자동화된 툴을 사용할 수 있다. 전문화된 곳에서는 자체적인 라벨링 툴을 만들어서 라벨링을 하는 곳도 있다. 하지만, 공개된 프로그램으로도 충분히 사용할 수 있는 툴들이 많은 터라, 이를 이용하였다.
- 라벨링 프로그램으로는 LabelImg, labelme, yolo_mark 등 여러가지 프로그램들이 있는데, 여기서는 yolo_mark 를 사용하였다. 다른 툴을 사용해도 된다. 다만, 라벨링은 사각형으로 지정하도록 하고, 최종 파일은 YOLOv5에서 학습시키기 위한 형태로 변환하는 작업이 필요하다. 자세한 것은 각 툴 사용법을 학습해야 한다.
- yolo_mark의 윈도우 버전 설치는 별도로 설명하지 않고, 관련 참고할 링크만 표시한다.(https://reyrei.tistory.com/20) 이 링크에서는 프로그램 설치/사용법만 참고하고, 실제 학습하는 과정은 yolov5와는 다르니 보지 말자.
-
- yolo_mark [이미지파일이 있는 폴더명] [이미지파일 리스트가 저장된 TXT파일명] [인식할 사물명칭] 을 입력하여, 실행한다.
- dir d:\work\data\train\image\*.jpg > train.txt 명령을 사용하여, 이미지 파일 목록을 파일로 만들어서 두번째 인자로 사용한다. 이것은 yolo_mark 프로그램에서 알아서 처리할 수도 있을 것 같은데, 왜 이것을 만들게 하는지 좀 이상함.
- 마지막의 세번째 인자는 다음과 같이 만들어 준다. obj.names 파일을 생성하고, 인식할 사물의 명칭을 입력한다. 인식할 사물명을 주욱~~~ 입력한다. 실제 진행했을 때는 노란색 신호와 차량, 안내판 등도 인식을 하도록 등록해두었다.설치한 yolo_mark 프로그램을 이용하여, 사진 파일에서 라벨링을 하였다.

-
-
- yolo_mark를 이용하여 라벨링하는 화면(좌회전, 직진)
-



-
-
- 라벨링 결과(txt 파일)
-



라벨링 결과는 이미지 파일명과 동일한 txt 파일이 생성되며, 박스를 친 좌표가 표시된다. 단위는 Pixel아 아닌, 사진의 크기를 1로 했을 때의 상대좌표로 0.xx 로 표시된다. 지금 기억으로는 중앙에서 떨어진 정도였던 것으로 기억하는데, 지금은 기억이 나지 않는다. 그냥 툴을 쓰면 되니, 넘어가자.
- 반복 학습을 시켜보자
- 이미지와 라벨링 파일(TXT)의 폴더 위치를 변경한다. 학습에 사용되는 훈련용 데이터로 train 폴더에 저장을 했다.
- 이미지 : d:\work\data\train\images 에 저장
- 라벨링파일: d:\work\data\train\labels 에 저장
- 나중에 조정하겠지만, train폴더와 동일한 폴더와 이미지/라벨링 파일을 만들어두자. valid 폴더는 모델의 일반화 능력을 높이기 위해 학습 중에 평가에 사용되는 검증 데이터로, 학습한 내용을 확인하는 모의고사 같은 것으로 보면 된다.
- 이미지: d:\work\data\valid\images 에 train의 파일들을 모두 복사
- 라벨링파일: d:\work\data\valid\labels 도 동일
- 위의 train과 valid에 저장된 파일의 개수 비율을 나줘준다. 자료를 보면 7:3 비율로 분리하면 좋다는 의견도 있고, 8:2가 낫다는 말도 있다. 이 비율을 자동으로 나눠서 배분해두는 명령도 있다. 물론, 프로그램으로도 나누는 것도 많이 나온다. 파이썬 코딩으로 몇줄이면 된다. 여기서는 그냥 돌아가는 것만 보려하는 것이라 그냥 그대로 복사를 해버렸다.
- d:\work\data\traffic.yaml 파일을 생성/저장해둔다. 내용은 다음과 같다.
- 이미지와 라벨링 파일(TXT)의 폴더 위치를 변경한다. 학습에 사용되는 훈련용 데이터로 train 폴더에 저장을 했다.
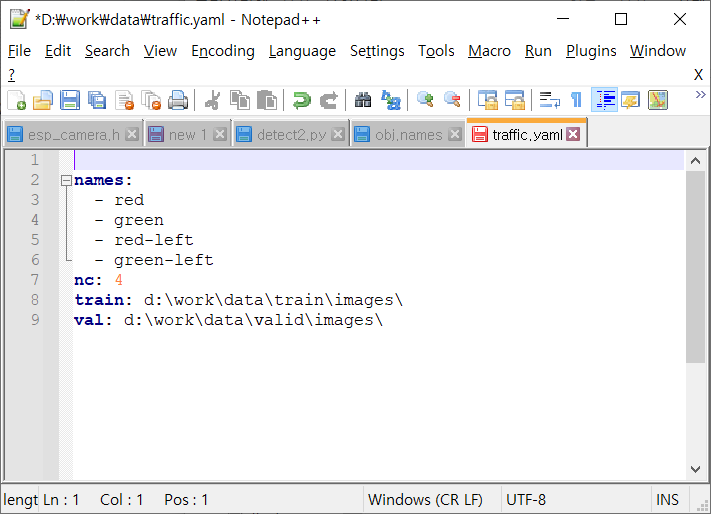
-
-
- 위의 names에 등록된 사물의 순서는 라벨링했을 때의 순서와 동일해야 한다. nc는 인식할 사물의 갯수를 지정하였다.
-
-
- yolv5가 설치된 폴더에서 아래의 명령어를 입력하여, 학습을 진행하였다. batch크기를 16개로, epoch 를 100번으로 하였다. 캡쳐한 이미지가 잘 안보여서, 원본 크기로 크게 붙여넣었다. 이미지 개수가 50개라고 한다면, (50/16)*100번이 반복 학습된다고 보면 된다.
- yolv5가 설치된 폴더에서 아래의 명령어를 입력하여, 학습을 진행하였다. batch크기를 16개로, epoch 를 100번으로 하였다. 캡쳐한 이미지가 잘 안보여서, 원본 크기로 크게 붙여넣었다. 이미지 개수가 50개라고 한다면, (50/16)*100번이 반복 학습된다고 보면 된다.


10번만 실행한 사례(결과: runs/train/exp3 폴더에 3.8MB의 last.pt 와 best.pt 가 만들어진다.)

6. 이제 사용해보자
- Command line으로 이미지의 사물을 인식
아래 명령으로 이미지 파일을 인식할 수 있는데, 학습 위한 파일 몇개로 몇번의 학습만으로는 좋은 결과가 나오지는 않았다. - 명령: python detect.py --source "d:\work\data\valid\images\IPC_2024-04-23.13.29.52.4700.jpg" --weights runs\train\exp4\weights\best.pt --view-img

- 결과(많은 데이터로 학습한 것): 초록색 신호등을 3개 모두 인식해야지 되는데, 1개만 인식한 것은 오류. T.T 기학습된 사진에서 트럭이 없었나 봄.

- 프로그램에서 사용하는 방법(사례)
- 새로운 것을 학습시키는 것은 이미지 수집 부터 라벨링, 학습 시키는 시간이 오래 걸린다.
- yolov5에서 제공되는 기본 학습 데이터(80개 사물 인식)를 이용해서, 응용프로그램을 만들어보자. 프로그램 설치부터, 아래의 100줄 안되는 소스코드 실행까지 두어시간에 모두 끝낼 수 있으리라 생각된다.
- 사무실에 웹캠을 설치해서, 프로그램이 사무실을 감시하게 한다.
- 사무실에 사람이 들어오게 되면, 프로그램이 사람이라는 것을 인식하고, 사진을 찍어서 텔레그램으로 보내는 기능이다.
- 또한, 사람이 나가거나, 또다른 사람이 들어와서 사람 숫자의 변동이 있을 때에도 텔레그램으로 사진을 보내는 기능을 만들어 봤다.
- 몇 줄 안된다. 물론, 텔레그램 전송을 단방향으로 보내는 것이라, 손을 추가로 봐야 하는데, 기능이 돌아가서 그냥 둔다.
- 아래의 코드를 수행하기 전에 필요한 패키지를 설치해야 한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
|
import cv2
import torch
import telegram
import asyncio
from PIL import Image
# 텔레그램 봇의 Key, ID는 지웠음. ***** 부분은 개인 키/ID로 등록 필요
chat_token = "***********:AAEBSeb5lLpBxvhfkjic1iXN7JkPM9Ln5os"
bot_id = '***********'
###############################################################
# torrent로 TEXT 보내기
###############################################################
def send_msg(msg):
bot = telegram.Bot(token = chat_token)
asyncio.run(bot.sendMessage(chat_id = bot_id, text=msg))
###############################################################
# torrent로 이미지 파일을 보내기
###############################################################
def send_img(send_image):
bot = telegram.Bot(token = chat_token)
asyncio.run(bot.send_photo(chat_id = bot_id, photo=open(send_image, 'rb')))
###############################################################
# 웹캠에서 영상 프레임을 얻어서, YOLO 모델을 이용하여 사람을 찾음
#
###############################################################
def yolo():
yolo_model = torch.hub.load('.', 'custom', 'yolov5s', device='cuda:0' if torch.cuda.is_available() else 'cpu', source='local')
# 0번: 사람
#
yolo_model.classes = [0]
# 웹캠에서 이미지 프레임 얻기
cap = cv2.VideoCapture(0)
ret, frame = cap.read()
i=0
num = 0
while True:
ret, frame = cap.read()
if frame is None:
break
# 프레임 10번째마다 YOLO 모델에 적용한다. 굳이 30fps으로 들어오는 웹캠
# 영상을 모두 분석하려면, 부하만 많이 걸려서 많이 skip하게 하였다.
i = i+1
if i != 10:
continue
i = 0
# YOLO모델 적용
results = yolo_model(frame)
results_refine = results.pandas().xyxy[0].values
nms_human = len(results_refine)
print(num, nms_human)
# 인식된 것이 없다면 영상 재인식
if nms_human <= 0:
num = 0
continue
# 화면에 출력하기 위해 해당 인식된 사물에 박스를 쳤다.
# imshow() 호출을 할 때에나 의미 있다.
for bbox in results_refine:
start_point = (int(bbox[0]), int(bbox[1]))
end_point = (int(bbox[2]), int(bbox[3]))
frame = cv2.rectangle(frame, start_point, end_point, (255, 0, 0), 3)
# 인식된 사물 변경이 있다면, 그 프레임을 파일로 저장하고, 텔레그램으로 전송
if num != nms_human:
cv2.imwrite('telegram_tmp.jpg', frame)
send_img('telegram_tmp.jpg')
num = nms_human
cv2.imshow("Video streaming", frame)
if cv2.waitKey(1) == ord("q"):
break
cap.release()
cv2.destroyAllWindows()
if __name__ == "__main__":
yolo()
|
- 휴대폰의 텔레그램 화면: 제 자리에 들어오는 사람이 있으면 촬영을 해서 텔레그램으로 전송되며, 인원수가 바뀌었을 때에도 사진 촬영/전송이 된다.

7. 더 해야할 것들은
- 실제 생활에서 보이는 사람 대신에 사물을 인식해서 처리할 수 있는 다양한 응용 분야로 갈수 있지 않을까.
- 사무실에 방문하는 사람이 있는지 여부를 검사하는 것은 초당 1프레임만 처리를 해도 될 수 있지만, 자동차 운전을 할 때 주변 차의 근접을 알려주는 것에 적용하려면 실시간성이 필요한데, 이것은 GPU를 이용해서 속도를 빨리하는 방법도 있겠지만, TensorRT를 이용해서 CPU에서도 약 20fps의 처리를 할 수 있는 수준으로 만들 수도 있다.
- 교차로 뒷편에 있어서, 앞차 꽁무니만 보이고 신호등이 안보일 때는 어떻게 해야 하나?
- 이 경우에는 앞차를 인식해서 앞차가 출발했을 때를 인식해서 안내하도록 해야 한다.
- 앞차가 출발했다는 것은 인식된 차량의 크기가 줄어들면 출발한 것으로 처리할 수 있다.
- 다른 센서를 사용하지 말고, 하드웨어는 카메라 하나만 두고 프로그램으로 커버할 수 있는 방법이 제일 낫을 것이라 생각하고 여러 고민을 해본다.
- 차량이 정지상태라는 것은 어떻게 인식을 할 수 있을까? 이것이 제일 어려웠다.
- 정지 상태에서는 앞차의 크기가 줄어들면 앞차가 출발한 것으로 인식을 하는데, 달리고 있는 차량에서는 어떻게 해야 할까?
내 차가 정지해 있다는 것을 앞차의 크기가 일정하면 정지했다고 인식했는데, 고속도로에서 서로 등속운전을 하고 있으면 어떻게 될까?
아니면, 옆차의 이동을 보고 내 차가 멈춰져 있는 것을 판단하는 것은 상대적인 위치이동이기 때문에 불가능하다. - 그러면, 주변의 고정된 사물을 인식하게 하고, 그 사물의 변화가 없으면 내 차가 서 있다고 인식을 해야 한다. 고정된 사물은 차선이 있고, 나무, 배경이 있다. 하지만 이 사물을 옆의 차가 지나가면서 가릴수 있기 때문에 이런 부분도 고민을 해야 한다.
즉, 카메라 하나로 차가 정지상태라는 것을 표현하기에는 많은 고민이 필요하게 된다. - 결론은 쉽게 가자는 생각으로, 300원짜리 가속도 센서를 하나더 추가하는 방법을 생각해본다.
- 정지 상태에서는 앞차의 크기가 줄어들면 앞차가 출발한 것으로 인식을 하는데, 달리고 있는 차량에서는 어떻게 해야 할까?
- 학습을 더 잘하게 하는 방법은 여러가지가 있다.
- 사물을 제거한 background 이미지를 넣어서 학습시키는 방법
- 이미지 개수를 늘리는 방법
- .... 많을 텐데... 그것은 나중에 전문으로할 때 고민해보자.
- YOLO를 사용하지 않고, 요즘 핫한 LLM으로 이것을 만드는 것은 더 쉬울수 있다. 사진을 찍어서, 신호등이 무슨 색인지를 물어보면 대답을 해줄 것이고 이 대답을 받아서 프로그램이 좌회전 신호로 바뀌었다, 직진 신호로 바뀌었다고 안내하는 것은 더 쉬울수 있다. 모든 사람이 새로운 LLM모델을 만들어내려고 고사양 자원과 시간을 들여서 개발을 할 필요없이, 분업하자는 차원에서, LLM을 이용한 응용 프로그램 개발자 입장에서는 너무 깊이 들어가기 보다는 다양한 업무에 어떻게 적용할지에 대한 고민만 하고 잘 만들어진 LLM을 가져와서 실행에 옮기는 것이 생산성을 높이는 것이 되지 않을까 생각된다.
- 참고사이트: https://github.com/ultralytics/yolov5/
8. 잡담
- 차에 카메라와 컴퓨터를 넣어야 한다. 아래의 문제점이 있다. 이를 개선하고 있다.
- 색상을 정확히 얻을 수 있는 카메라가 필요하다.
- 광각 카메라가 아닌, 외곡이 없는 앞에 있는 이미지를 그대로 담을 수 있는 카메라를 구한다.
- 차량에 달았을 때, 터널을 통과할 때, 야간 운전시의 빛 번짐, 빛이 강할 때의 빨간신호등이 하얗게 보이는 현상들이 현재 USB카메라에서 나타난다. 딱 맞는 카메라를 찾아야 한다.
- 컴퓨팅용 서버는 Nvidia의 Jetson Nano 4G 모델로 했다.
- 라즈베리파이3에서 돌리게 하는 것도 가능한데, 이것은 TensorRT를 적용해야지 속도가 좀 나올 것 같다.
- 차량 전원이 꺼졌을 때, 컴퓨팅용 서버(Jetson Nano)가 안전하게 shutdown되게 해야 한다.
- 보조배터리를 다는 방법은 추가 비용도 들지만, 폭발할 수 있어서 배제하였다.
- 최종적으로, time delay 회로를 이용하여 시동이 꺼진 것을 인지하고 차량의 배터리를 이용해서 서버(우분투)가 켜져 있도록 한 후에, shutdown을 자동으로 호출되게 한다. 30초면 shutdown되기 때문에, 차량 시동용 배터리 방전되지는 않을 것이다.
- 회로는 총 3가지로 구성하였다.
- 시간지연회로: 시동이 꺼진 후에도 1분동안 상시전원(차량배터리)에서 전원이 공급되게 한다. (1분 이후, 완전 차단)
- 전압 스텝다운회로: 12V를 5V로 Down시켜서 컴퓨팅용 서버에 전원을 공급한다.
- 마지막으로, 차량의 시동이 꺼졌다는 것을 인식하고 컴퓨팅용 서버의 GPIO 디지털 핀으로 시동꺼짐 디지털 시그널을 보내는 역할을 하는 포토커플러로 만든 회로가 있다.

우측 아랫쪽의 젯슨나노 디지털 입력으로 시동 여부 Signal 넣는 회로(포토커플러 이용). 포토커플러를 이용한 회로는 왼쪽/오른쪽의 회로가 광학적으로 연결되어있을 뿐, 완전히 전자회로 측면에서는 분리되어있어서 이런 스위치 용도로 자주 사용된다.


위의 전체 3가지 모듈을 결합한 최종 모습이 아래와 같다. Time Delay 모듈과, 스텝다운 모듈은 범용적으로 많이 나오기 때문에, 직접 만들때 보다 5배 정도는 싸게 잘 만들어진 것으로 구할수 있다. 3가지 모듈을 연결해서 만들었고, 차량과 Jetson Nano(우분투)에 연결해서 안전하게 운영할 수 있게 된다.

'Jetson & 머신러닝' 카테고리의 다른 글
| python 가상환경(venv) 사용하기 (0) | 2024.07.08 |
|---|---|
| 아주 간단한, 우분투 전원버튼으로 자동 Shutdown 종료 방법 (0) | 2024.07.08 |
| yolov8 설치 on Jetson xavier (0) | 2024.07.01 |
| torch / vision 설치 on Jetson Xavier (yolo GPU학습용) (6) | 2024.07.01 |
| Jetson Xavier에서 부팅할 때, 자동 실행(데몬) (0) | 2024.07.01 |